智课方舟复盘
本博文主要想谈谈博主在《智课方舟》项目中的收获。这是16届服创赛中超星出的题目,赛题链接请见赛题链接。不过本博文不会聚焦具体的比赛形式之类,会侧重以开发者/后端开发成员/项目成员来说一些自己学到的微不足道的经验。
不过很荣幸项目获得了国三,并且最主要的是学到了很多东西。很感谢大家愿意带我玩😁。这里附上仓库链接,欢迎star https://github.com/class-scheduling-system 。
本文主要谈论的是,个人对项目宏观层面的一些理解,个人在开发中学到的东西(主),以及团队协作的一些规范。
因为文章有些长,所以可以点击右侧的导航栏进行重点索引。
系统架构
系统架构
从本项目中学到的,以及其他项目中验证实施的是,系统的架构很重要。
并且你要清楚你在本次项目中的身份定位。作为开发者,了解架构对开发有很大的帮助;作为同时负责架构的人员,那么一个好的架构绝对是很重要的了。
系统架构图至关重要,善画Mermaid图。定义好过程走向和JSON数据对接。
这里给出了一个通用的Web应用流程图(视具体的项目而定,很多地方是用不到的,注意甄别)。
graph TD
%% 定义样式
classDef client fill:#e1f5fe,stroke:#01579b,stroke-width:2px;
classDef gateway fill:#fff9c4,stroke:#fbc02d,stroke-width:2px;
classDef app fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px;
classDef data fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px;
classDef external fill:#eeeeee,stroke:#616161,stroke-width:2px,stroke-dasharray: 5 5;
subgraph Client_Layer [客户端层]
User((用户 User)) -->|操作| Browser[React / Vue SPA]
User -->|操作| Mobile[Mobile App]
end
subgraph Gateway_Layer [接入层/网关]
Browser -->|HTTPS / JSON| Nginx[Nginx 反向代理]
Mobile -->|HTTPS / JSON| Nginx
Nginx -->|负载均衡| APIGateway[API Gateway / Filter]
end
subgraph Application_Layer [应用服务层 Spring Boot]
APIGateway -->|Request| Controller[Web Layer: Controller]
subgraph Logic [业务逻辑内部流转]
Controller -->|DTO -> DO| Service[Service Layer: 业务逻辑]
Service -->|AOP| LogAspect[日志/权限切面]
end
Service -->|ORM / MyBatis| DAO[DAO / Mapper Layer]
end
subgraph Infrastructure_Layer [数据与基础设施层]
Service -.->|读写热点数据| Redis[(Redis 缓存)]
Service -.->|异步解耦| MQ>RabbitMQ / Kafka]
Service -.->|文件上传| OSS[对象存储 MinIO/S3]
DAO -->|持久化| MySQL[(MySQL 主库)]
MySQL -.->|主从同步| MySQL_Slave[(MySQL 从库)]
end
%% 样式应用
class User,Browser,Mobile client;
class Nginx,APIGateway gateway;
class Controller,Service,DAO,LogAspect app;
class Redis,MySQL,MySQL_Slave,MQ,OSS data;
%% 补充说明
linkStyle 2,3,4,5,6,9,12,13 stroke:#333,stroke-width:1px;
以及你的技术选型(前端技术,后端技术,数据库,安全与认证.etc),系统组件设计,性能考虑等等。
之前有一次有个朋友让我帮忙看代码,我会发现他的项目中还有kafka,但是很多一些其他的地方设计的又过于简单,结合他具体的业务需求来看这是不正确的。在问的过程中也差不多知道了问题。当然建议你有结构性思维,刚开始想好大致的方向,无论什么时候多思考。同时经验当然也很重要的啦。
接口文档
并且要从抽象架构中具体分离出来功能点,先写好接口文档,规定好内容,然后前后端再一起协同开发。避免一方开发超出预期,偏离方向。(博主后面自己做全栈开发的时候,就陷入过先写前端还是先写后端的二元选择,会出现一方过度偏离刚开始设计的情况!)
在实际执行中,设计先行,开发并行是最高效的。不要单纯陷入“先写前端”还是“先写后端”的二元选择,而是要采用工业界最标准的流程——“API First”(接口优先/契约驱动)的设计模式。
核心逻辑:前后端是两个独立的系统,他们呢通过API(契约) 通讯。只要契约(JSON结构、HTTP方法、错误码)定好了,前后端就可以完全解耦,并行开发。
并且建议你善用GitHub里面project里面的这个东西,无论是对于个人开发还是团队协作,都有很大的帮助。
个人开发
个人在负责自己的那一块的时候,如果刚开始开发遇到难度,可以画流程图。不要懒,这个很有帮助的。
本人负责的是后端接口的开发,会着重说这方面相关的东西。
架构层次
关于具体的三层架构,有以下需要注意:
表现层:Controller
业务逻辑层:Service
数据层:DAO/Repository
每层要各司其职。在此之前先讲一下各个层需要的东西,
实体与模型(Model/DTO):
不要把数据库实体直接扔给前端,那是大忌。要用DTO(Data Transfer Object)做隔离。
表现层(Controller):只负责调度。
POJO:本质:一个简单的Java类,不受特定框架的限制。通常是以下各类对象的统称或基础:JavaBean, DTO, PO, VO。
绝大多数的Entity和DTO本质上都是POJO,但它们被赋予了特定的功能角色。
接下来简单的说一下架构层次。
首先展示一下我们项目中的src下的文件树结构: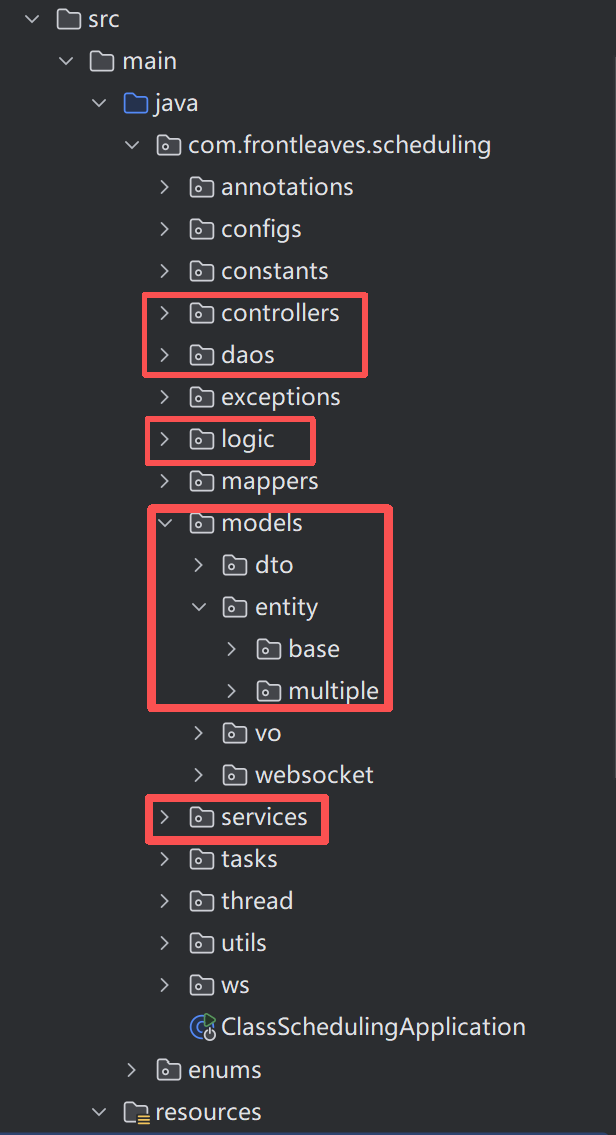
图中我标注了一些通用常用的部分。简单进行一下讲解:
POJO:
models目录下看到的这些,统称为POJO。它们的区别完全取决于给谁看。
- Entity/DO:数据库表映射。
- 本图中叫Entity,有时也叫DO。
- 它和数据库里的表是1:1严格对应的。表里有user_id,这里就有userId。
- 注:绝对不能把这个直接扔给前端!因为这里面可能包含password,is_deleted这种内部字段,泄露了就是重大安全事故。
并且关于Entity和DO这两种说法,我也是专门查了下资料:
- DTO:只包含数据,不含逻辑,用来传输。
(数据传输对象,用户前后端交互)- 它是用来在Controller和Service之间搬运数据的。
- 比如前端发来一个注册请求,包含username和password,这就封装成一个UserRegisterDTO。它比Entity灵活,可以是多个表的组合,也可以是某些字段的子集。
- VO:给前端展示用的,用的比DTO少。(视图对象,用于前后端交互)
- 这是专门给前端(React/Vue)或客户端(App)看的。
- 为什么要分VO和DTO?
- 比如UserDTO里有birthDate,但前端界面只需要显示“xx岁”,那你就可以在UserVO里算好 age: 25 再传过去。或者为了脱敏,把手机号中间四位变成**** 。(结合DTO看)
- 为什么用的少?
- 很多为了省事的开发(或项目没有那么复杂),直接把DTO甚至Entity扔回去了。(虽然并不提倡,但这是现状)
核心逻辑层:
- Service(逻辑接口层)
只定义“要做什么”(如login(), getSchedule()),不写“怎么做”。这是为了利用Java的多态性。 - Logic(实现层)
本项目独特的地方。一般用的是service/impl/
对Service进行实现。通常位于Service和Controller之间,用来处理跨多个Service的复杂业务聚合。
神秘的Mapper和DAO:
本项目用到了MBP(MyBatis-Plus)。
这东西真的很好,目前国内Java生态的“大杀器”。建议可以和JPA(Hibernate)和MyBatis一块做下对比。
给我的感觉就是,它在“JPA(Hibernate)的语句简单,但是精细度不够,要精细就要写很多语言”和“MyBatis做到精准控制,但是要写的语句太多”之间取得了很好的平衡。
至于具体框架的选择,当然还是建议具体项目业务具体分析咯。不过也多说JPA(Hibernate)在国外很常用,国内尤其大厂比较青睐MB(P)。不过我们这个项目数据表是真的超级多,我感觉这也是我们选择这个框架的其中一个原因。
回归正题。
我截取了其中一个Mapper文件的内容,并以此为例。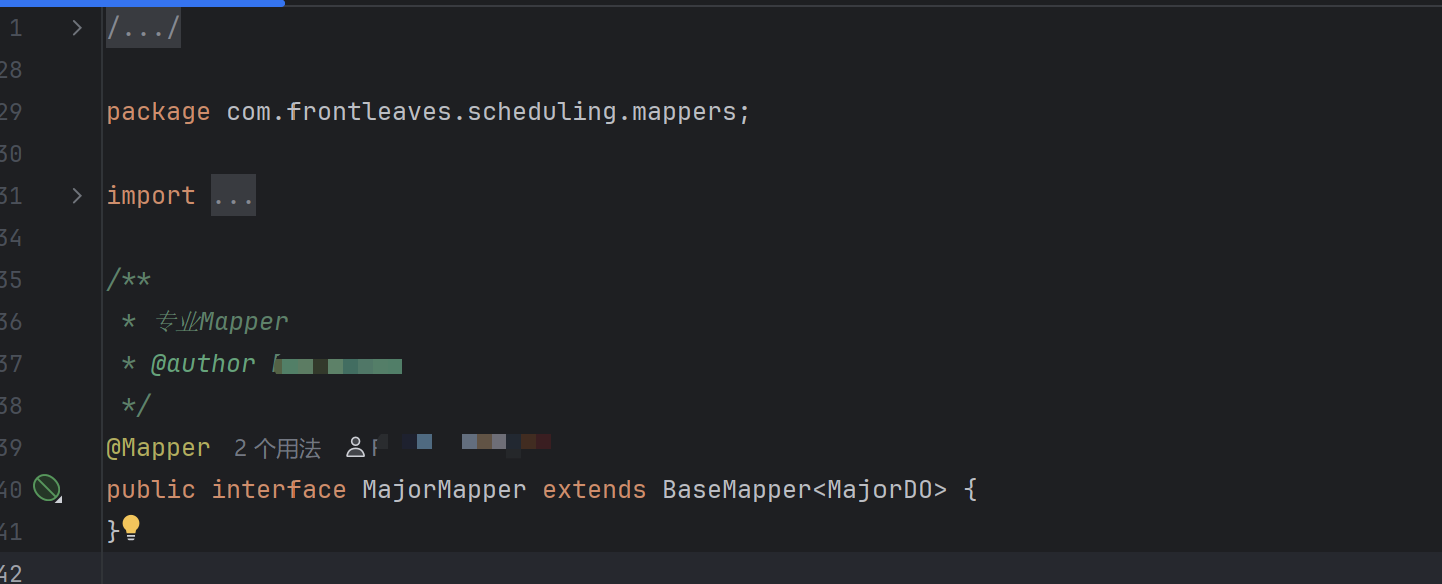
Mapper(MBP的核心)
BaseMapper<XxxDO>,是操作数据库的神器。- 看
extends BaseMapper<MajorDO>,只要写了这一行,MajorMapper就自动拥有了insert,delete,update,selectById等十几种方法。(继承后,MBP会自动提供CRUD功能)
不过要注意,MBP的BaseMapper只能帮你搞定单表操作。但当你需要连表查询、复杂排序或特殊业务逻辑时,就需要在Mapper额外定义方法。举个例子:
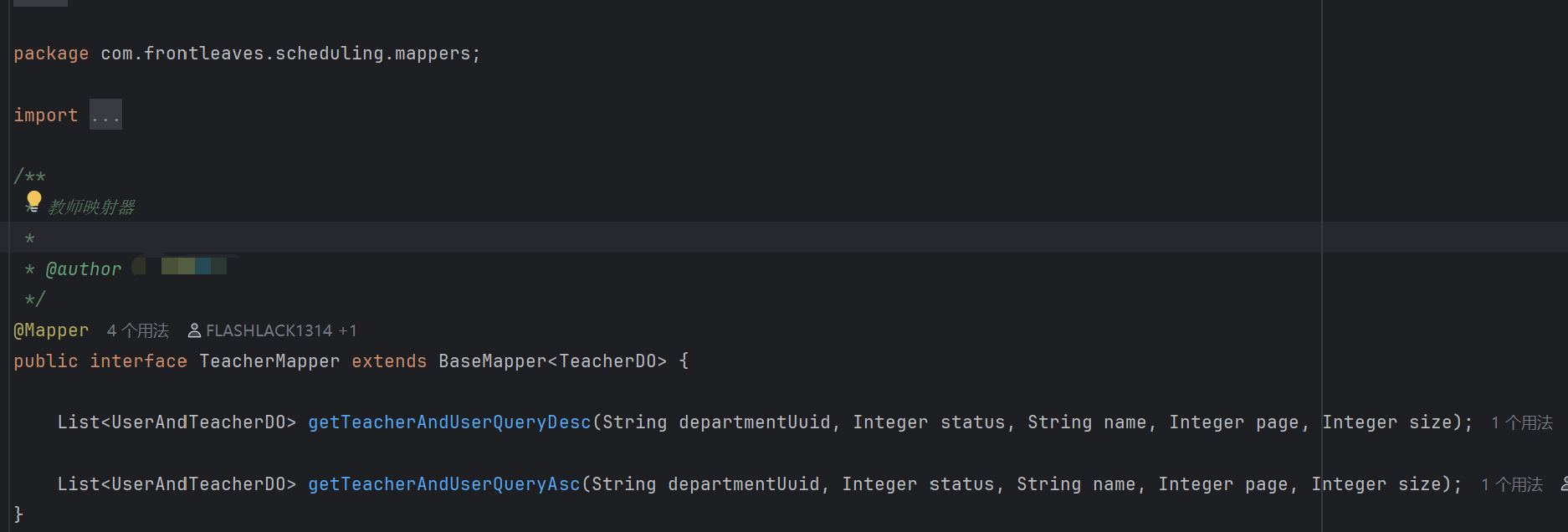
然后自定义sql的xml文件写在src/main/resources/mapper。
DAO
我仔细看了,发现我们这边的设计和其他的不算一样。
本项目中:被赋予了“缓存管理”和“MBP增强”双重身份。
业界通常做法:- Mapper:继承BaseMapper,只管SQL
- Service(Interface):继承IService
- ServiceImpl(Class):继承ServiceImpl(在MBP的官方文档中是建议给Service实现类去继承的)。所有CRUD、缓存注解(@Cacheable)、事务注解(@Transactional)通常都写在这里。
- DAO:在MBP体系下,通常不存在单独的DAO。Mapper就是DAO。
我们的做法:
- 额外增加了一层DAO层,让它继承ServiceImpl
- 好处:手动控制Redis逻辑更灵活(比@Cacheable注解更灵活)
- 坏处:多写了一层代码(?。结构变复杂了。
客观评价是,虽非“标准教科书”式,但在重缓存、高并发的实战场景下,其实是非常实用且强悍的。为了精细化控制Redis花村一致性,并减轻Logic层的负担,特意设计了厚DAO层。
简单讲: - Logic是指挥官,负责打仗(处理业务)
- DAO是军需官,负责高物资(拿数据,不管是仓库里的还是口袋里的)
- Mapper是苦力,只负责搬运(执行SQL)
所以!数据的流转路线为:
- 用户请求->到了Controller(Web层)
- Controller->拆解参数,封装成DTO
- Controller->呼叫Service(接口)
- Logic(Service实现类)->接单。这里是业务的大脑,负责复杂的计算和调度
- Logic->呼叫DAO层(不是直接叫Mapper)
如:studentDAO.getStudentByUuid(id) - DAO层(关卡)->执行“潜规则”:
- 先查Redis: 有数据?直接返回,不用惊动数据库
- 没数据?->呼叫Mapper
- Mapper->自动生成SQL,去Docker里的MySQL抓取DO(Entity)
- DAO层->拿到DO,反手写入Redis缓存,然后返回给Logic
- Logic->拿到DO,进入业务计算,最后转换成VO
- Controller->拿到结果,最后返回给前端
流程图:
graph TD
%% 定义样式
classDef user fill:#e1f5fe,stroke:#01579b,stroke-width:2px;
classDef controller fill:#fff9c4,stroke:#fbc02d,stroke-width:2px;
classDef logic fill:#e8f5e9,stroke:#2e7d32,stroke-width:2px;
classDef dao fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px;
classDef infra fill:#eceff1,stroke:#455a64,stroke-width:2px;
%% 节点定义
User((User / Client)):::user
Web[Controller 层]:::controller
Service[Logic 层 <br/> Service Impl]:::logic
DAO[DAO 层 <br/> ServiceImpl + Cache]:::dao
subgraph Infrastructure
Redis[(Redis Cache)]:::infra
Mapper[Mapper Interface]:::infra
DB[(MySQL DB)]:::infra
end
%% 流程连线
User -- 1. 发起请求 --> Web
Web -- 2. DTO封装 & 校验 --> Service
Service -- 3. 处理业务 & 请求数据 --> DAO
%% DAO 内部逻辑
DAO -- 4. 查询 Key --> Redis
Redis -- Hit? --> DAO
DAO -- 5. Miss: 呼叫Mapper --> Mapper
Mapper -- 6. 生成SQL --> DB
DB -- 7. 返回 Entity (DO) --> Mapper
Mapper --> DAO
DAO -- 8. 回写缓存 (Put) --> Redis
%% 返回流程
DAO -- 9. 返回 DO --> Service
Service -- 10. 计算 & DO转VO --> Web
Web -- 11. 返回 JSON --> User
建议是自己画一下更明晰喔。
关于单元测试。
在系统架构模块说了比较多的相关的层次结构。所以不难判断,我们主要要对DAO和Logic做单元测试。
- 关于DAO:不仅仅是查库,还有大量的逻辑(缓存逻辑、级联删除、数据一致性)。它是数据安全的底线。
- 关于Logic:测的是业务。在测Logic时,应该Mock掉DAO层
模块之间相对独立性
注意模块之间的相对独立性,合理解偶。
DAO:需要保存数据库操作原子化,并且使用缓存机制。
Logic:专门处理数据逻辑。
Controller:接收数据,对数据进行校验以及引导如何进行Logic操作。
关于注解(简单版|可跳过)
代码里的每一个注解都是为了解决一个痛点。善用注解。
@Entity:
- 是JPA(Hibernate)的注解,用于标记Java类为数据库实体。
- DO(Data Object)层才是与数据库表直接对应的实体类层。
通过定义也不难看出,@Entity应当用于DO层。(VO和DTO等都不该使用@Entity)
MBP用不到它:
DO层常见注解:
@Data: 没啥好说的
@TableName(“xx_xxx”):表名
@Accessors(chain = true): 开启链式调用
@NoArgsConstructor: 无参构造。很重要!原因:
- MBP需要无参构造,在反射创建对象时需要。
- 反序列化需要无参构造:JSON转对象时需要。
- Spring Bean创建可能需要:某些场景下需要。
VO层:
@Getter
@NoArgsConstructor
@AllArgsConstructor
解答为什么只使用@Getter:
- VO是“视图对象”,主要用于接收前端参数
- 不需要@Setter, 是因为:
- 通过构造函数赋值(@AllArgsConstructor)
- 使用框架的反射赋值(如Spring MVC)
- 避免被意外修改(不可变对象更安全!)
- 为什么不是@Data?
- @Data = @Getter + @Setter + @ToString + @EqualsAndHashCode + @RequiredArgsConstructor
DTO层:
@NoArgsConstructor
@AllArgsConstructor
@Data:
- DTO是内部传输对象,需要可变性
- 不同层之间转换时可能需要改变属性
DTO层只需包含需要传输的字段即可。如password,createdAt, updatedAt等均不能包含。
@Data滥用问题
上面简单的提了一嘴,@Data不能滥用,@Data = @Getter + @Setter + @ToString + @EqualsAndHashCode + @RequiredArgsConstructor
这里解释一下:
@Data的潜在危害:
- equals/hashCode问题:对象放入集合后修改会出问题
- toString泄露敏感信息:日志可能输出密码等敏感字段
- 意外添加setter:再需要不可变的场景(如VO)破坏不可变性
- 构造函数不符合预期:@RequiredArgsConstructor可能不满足需求
项目业务对安全需求极高的话需要注意了。
本项目中没用到但是还不错的注解:@Builder
在没有@Builder前,创建复杂对象通常面临以下尴尬:
- 构造函数地狱:若一个类中有10个属性,需写一个包含10个构造参数的构造函数。调用时极易弄错参数顺序。
- Setter繁琐且不安全:使用Setter赋值会导致对象在创建过程中处于“半成品”的不稳定状态,且无法轻松创建不可变对象。
核心作用:@Builder会在编译时自动生成: - 一个名为
类名Builder的内部静态类。 - 内部类中包含于原类属性对应的方法,这些方法返回builder本身(实现链式调用)
- 一个build()方法,负责调用全参构造函数并返回最终的对象实例。
代码示例对比:
传统方式(使用构造函数):
1 | // 必须记住顺序:id,name,email,age,phone... |
使用@Builder方式:
1 | import ... |
注:由于@Builder内部需要调用全参构造函数,若手动写了其他构造函数或者加了@NoArgsConstructor,通常建议同时显示加上@AllArgsConstructor。
根据个人犯过的错误进行的一些总结
- 如果要用到@EnableCaching的话,要放置在专门的配置类中,而非直接放在启动类上。这样可以更灵活地在不同环境(如单元测试)中根据需要启动或禁用缓存功能。
一般情况下,不要编辑Application主类。 - 要有结构性思维,不要造轮子。多学学团队里面是怎么做的。
- 对于日志,使用info的时候,意思是告诉客户这个日志内容,若只是开发人员测试用的应该是debug或trace。
- Controller层的xxxUuid大多要进行正则判断。该层数据验证较多,勿忘数据验证。
- 经常用的常量写在StringConstant里。
- 业务抛出使用BusinessException。(自己项目要自己定义嗷)。有错误使用throw抛出(非ResultUtil.error)
- 主键禁止修改。(一般情况下只用作拆线呢,不允许uuid类型主键修改)若uuid修改导致更新失败(因为修改后的uuid,在数据库中可能不存在)
反例:

- 数据操作原子化:
反例2:

用lambda做map操作的想法很好,不过在数据库中为了保证数据库操作的原子化,DAO输出的数据有可能被其他Logic使用,需要保证数据原子化。并且获取的数据应该是属于原始数据。
即:输出应该使用MBP的Page,泛型是用xxxDO进行输出,格式转换应该由Logic进行,DAO只处理数据库的操作,一切逻辑交给Logic。 - MBP方法用在DAO,在Mapper属于侵入。
- DO不要出现在Controller层。DO本身是对数据库进行操作,不该出现在控制层。控制层主要处理数据验证,Logic走向(如何进入服务层)。
且若提前抓为DO,那么VO和DO比 大部分情况下VO数据量较少。那么转为DO会有很多数据是空数据,需额外花精力对数据是否为空或者进一步逻辑操作做考虑。
VO可以直接拿到数据对数据进行处理,处理完后一起合并为DO。
尤其是VO部分数据是可以填写的情况下,转为DO,有些位置原本是空的,和部分选填位置是空的,就会造成数据验证麻烦,要自己去验证数据一个个去比对。
反例3:
- 选填为空代表查询条件为空,没有查询条件,不是不需要查询内容。
- 新建的DO直接转成DTO数据不完整,要从数据库重新提取数据(如:缺少用户主键、创建时间和删除时间,及部分数据库自动填写的数据)
- 创建用户不应该出现UUID,创建用户的UUID应该交给系统自行创建。
反例4:
- 需对外键约束做判断、验证。若数据传入错误或格式错误均会报未定义过的错。
- 工具类不要使用注入(侵入式),尽量用static。否则多处重复调用容易造成Bean反复注入。
反例5:
- 在DAO里,若找不到数据应该返回null(而非存在该实体),所以逻辑层要起到保险作用 要判空,并且判空后保证返回用数据正常应该不可以返回null
- 不建议DAO转义后返回数据,数据转换格式推荐在Logic进行(方便扩展可以直接复用该接口)
团队协作
注意提问的智慧
关于提问的智慧。对我个人来说,一般情况下,在我有了自己的思考理解并进行过探索,但是还是解决不了的问题,我会去问别人。这样会让我更好的理解问题。
提问的智慧是一门很好的学问。无论在技术领域还是日常生活之类的地方都很扮演着很重要的角色。也常常在网上可以看到这样的梗图,“没有日志没有截图没有反馈,那我只能给你算一卦了”。

并且最好的话还是要截图或者文字。如果每一次都是拿着手机对着你的电脑屏幕在拍的话,感觉还是会有一些不好哦。
此外,礼貌和尊重在很多情况下都是加分项。我尊重每一个教我东西的人。我个人来说也是很爱帮助别人的,不过也有一些情况,比如我认真详细地回答了你,然后你人没了,那以后我有一定概率可能就不会再教你了。😉
关于git
一些常见的git用法就不说了哈,相关技术教程博客应该都讲的蛮多、蛮清楚的了。这里主要结合项目、具体的编辑器(以IDEA为例)说一些比较实用的。
经常进行git 提交
个人用Jetbrains家的编辑器更多一些,它很好用,用起来很舒服。
对文件修改后经常提交推送,这样很有帮助,有利于队里其他成员知道你目前的动态,协进开发流程,同时当你其他地方有问题不得不重置的时候,也减少了一些麻烦。
建议下载一个通义千问插件,
点击你需要提交推送的文件,然后再点击通义灵码,就可以生成提交内容啦!
嗯如果你恰好还有SonarQube这个插件的话,它还可以告诉你一些提交内容中不规范的编码、有错误的编码,给你修改建议。这个在coding中也会让你的代码变得很规范。
或者你也可以直接通过终端命令进行提交,不过个人觉得这种还是更方便亿些。
然后关于git commit的相关写法,以及分支新建原则,见3.3。
可输出中文的 git diff
git diff master[你的主分支]…HEAD –output=pr_changes.diff [自己起的文件的名字]
这个是本分支上已经提交的记录和主分支相比的差异。
虽然输出的文件的内容蛮少的,才几行,但是效果特别好。这时你可以把这个文件扔给你的AI,让它按照pr描述给你,md语法格式,禁止emoji表情(如果你不需要)。
此外,已经pr过了,你再修改文件,一次提交推送,就会直接到你pr的那部分(相当于你的最新修改又整合进去了)。常见于CR(Code Rewiew)前或者CR过程中、你被打回修改的情况。
如果审批过了的话,你再修改很多文件(还在同一分支上),多次提交,还是需要再打PR。
不过也有说分支没用了后就可以安全删除,但是个人觉得没必要,有迹可循会让代码更安全。并且之前团队协作中也没有删过这个。(之前有朋友问过,想到再提一嘴)
分支新建原则 & git commit规范
分支新建大多数是这种形式:feature/get-user-info (我举个例子)。
每次新建分支,要将master分支(或者develop分支)合并到当前分支(避免产生冲突)。
develop分支(如果有的话)也就是最新的分支了, 开发分支;master是比较稳定的分支。不过现在也多叫main,其实没多大区分的。
git commit规范提交的原因就不多说了。从反面看:
- 团队协作时,别人看不懂你的提交意图(比如“修复了那个问题”——到底哪个问题?);
- 想回滚代码时,翻遍提交记录找不到关键节点;
- 用工具生成Changelog(更新日志)时,全是无效信息,只能手动整理。
而规范的Commit信息,本质是“给代码变更写说明书”:既方便自己追溯,也能让团队快速了解每一次提交的价值。
注意这个:type(scope): subject
type:提交的”类型”(必须)
这是最核心的部分,用一个词说明“这次提交到底做了啥”。只能用下面这些值:
| type值 | 含义 | 例子 |
|---|---|---|
| feat | 新增功能(最常用) | feat(登录):新增短信验证码登录 |
| fix | 修复bug(最常用) | fix(购物车):修复空车结算报错 |
| docs | 只改了文档(如README) | docs: 更新API文档的参数说明 |
| style | 代码格式变更(不影响逻辑) | style: 统一用单引号代替双引号 |
| refactor | 重构(既没加功能也没修bug) | refactor(支付):拆分支付逻辑函数 |
| perf | 性能优化 | perf:优化列表渲染速度 |
| test | 新增/修改测试代码 | test: 给登录功能加单元测试 |
| build | 构建工具/依赖变更 | build: 从npm换成pnpm |
| revert | 撤销上一次提交 | revert: 撤销"feat:新增xxx" |
| chore | 辅助工具变动(不影响代码) | chore: 配置ESLint规则. |
scope:提交的”影响范围”
说明这次提交影响了项目的哪个部分,让读者快速定位范围。没有固定值,按项目实际情况写就行:
- 小项目可以写“模块名”:如
feat(用户模块): ...、fix(订单页): ...; - 大项目可以写“层级/功能”:如
feat(API): ...(接口层)、fix(UI): ...(视图层); - 如果影响范围太大(比如重构了整个项目的工具函数),可以省略scope:
refactor: 统一工具函数命名。
subject:提交的”简短描述”(必须)
用一句话说清“具体改了啥”,有3个硬性要求:
- 开头小写(除非是专有名词,如“UI组件”);
- 不超过50个字符;
- 结尾不加句号(简洁为主)。
反例:feat(登录): 新增了一个短信验证码登录的功能。(结尾有句号,且“新增了一个…功能”太啰嗦)
正例:feat(登录): 新增短信验证码登录(简洁明确)
几个常见正例:
fix(购物车): 修复商品数量为0时仍可结算的bug(fix+明确scope+具体问题)feat(个人中心): 新增头像裁剪功能(feat+模块名+功能说明)refactor: 拆分utils工具类(按功能分类)(无scope+重构说明)docs(API): 补充支付接口的错误码说明(docs+接口层+文档变更)perf(列表): 用虚拟列表优化长列表渲染(perf+功能+优化方式)
团队协作
比较综合的东西。可结合 1.2 接口文档、3.1 提问的智慧等 一块看。我们会在群聊里面说一些信息问题,但是更多情况下比较正式的 还是在GitHub上接口文档下面来进行提问和疑问解答。
这里不再截图,自行查看上面的链接嗷~
感觉好的团队真的很好,不仅仅指技术上的合作、学习,相处起来也非常舒服。我非常幸运能够有这样的经历。
其他
一些其他小标准:注意写JavaDoc文档。这个要自行实践。希望你不仅编码符合规范,注释之类也很标准。这是职业素养的加分项。
JavaDoc格式:

然后注释嘛 其中一点规范的 就是要用英文啦。但是目前个人还是中文更舒服一点👉👈… 努力走向国际化吧。
不过也听技术圈有人会说,写的太好反而会被炒。我的看法就是 你可以懒、有“坏点子”,但是你不能真的不会。懂得都懂,不举例哈。单元测试。我们长写的是dao层和logic层,因为这里面毕竟和逻辑相关的多嘛。在第二小节中也提到过。
测试相关的,ApiFox测试啦,单元测试,集成测试之类。需要会。
现在也有cc之类的自动化测试都可以搞了。看法是要自己懂,在此基础上借助东西提高效率。IDEA中数据库要点击到整个目录(你所在的数据库)才是更新,不能是目录下的一个。也是犯错后,偶然间经指点才懂的,很有趣。
小结
那么差不多就是这些啦。第一遍完整复盘可能会有遗漏或者有地方理解仍然不正确。欢迎大家指正。
再次感谢。
 WeChat
WeChat AliPay
AliPay




